2014年2月4日,Cloudera宣布CDH支持Spark,在CDH 4.4中引入Spark 0.9。
http://vision.cloudera.com/apache-spark-welcome-to-the-cdh-family/
在引入的时候强调了三点:
1. Machine Learning
2. Spark Streaming
3. Faster Batch
2014年7月,在github上创建了Apache HBase与Spark的集成项目SparkOnHBase
http://blog.cloudera.com/blog/2014/12/new-in-cloudera-labs-sparkonhbase/
https://github.com/cloudera-labs/SparkOnHBase
当前SparkOnHBase主要集中在这几个方面的功能改进:
1. 在MR的map或者reduce阶段对HBase的全量访问(Full Access);
2. 支持bulk load;
3. 支持get, put, delete等bulk操作(bulk operation);
4. 支持成为SQL engines。
2015年8月SparkOnHBase项目有了里程碑似的进展,被提交到HBase的主干(trunk)上,模块名为HBase-Spark Module,HBASE-13992 。
http://blog.cloudera.com/blog/2015/08/apache-spark-comes-to-apache-hbase-with-hbase-spark-module/
https://issues.apache.org/jira/browse/HBASE-13992
HBase-Spark module相比于SparkOnHBase在架构上没有什么变化: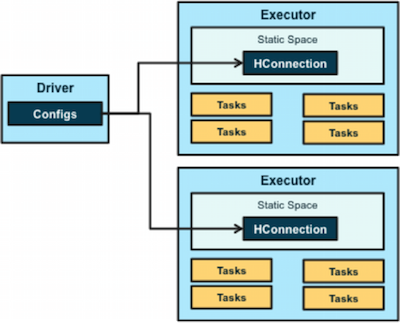
在具体实现上当前有三点改进:
1. 使用了全新的HBase 1.0+的API;
2. 从RDD和DStream functions操作HBase的直接支持;
3. 简化 foreach 和 map functions;
计划工作有两项:
1. Spark-HBase Module支持bulkload;
2. Spark-HBase Module支持Spark DataFrame DataSource;
https://issues.apache.org/jira/browse/HBASE-14150
https://issues.apache.org/jira/browse/HBASE-14181
实际上集成Spark作为计算引擎的项目还有Hive和Pig:
http://www.cloudera.com/content/cloudera/en/products-and-services/cdh/spark.html
http://blog.cloudera.com/blog/2015/02/download-the-hive-on-spark-beta/
http://blog.cloudera.com/blog/2014/09/pig-is-flying-apache-pig-on-apache-spark/
参考:
http://blog.cloudera.com/blog/2015/08/apache-spark-comes-to-apache-hbase-with-hbase-spark-module/
https://github.com/cloudera-labs/SparkOnHBase
http://blog.cloudera.com/blog/2013/11/putting-spark-to-use-fast-in-memory-computing-for-your-big-data-applications/