资料参见文档:http://wenku.it168.com/d_001428550.shtml
版本:
1. Hadoop: 基于 Hadoop 2.2 的阿里定制版
2. HBase: 基于 HBase 0.94 的阿里定制版
部署方式:
1. 服务总数近1000台,分2个集群;
2. Hadoop/HBase共同部署;
分析:服务器数量可能是2014年初的数据;HBase部署方式可能是RS和DN部署在同一个节点上。
服务器配置:
1. CPU:24/32 Cores
2. Memory:48G/96G
3. Disk:12 * 1T SATA Disk 或者 12 * 2T SATA Disk
分析:服务器配置计算能力比较强,内存和磁盘配置都不是很高。
大数据组件:
1. HDFS + YARN
2. HBase
3. MR
4. iStream
5. Spark
6. HQueue
7. Phoenix
8. OpenTSDB
9. Zookeeper
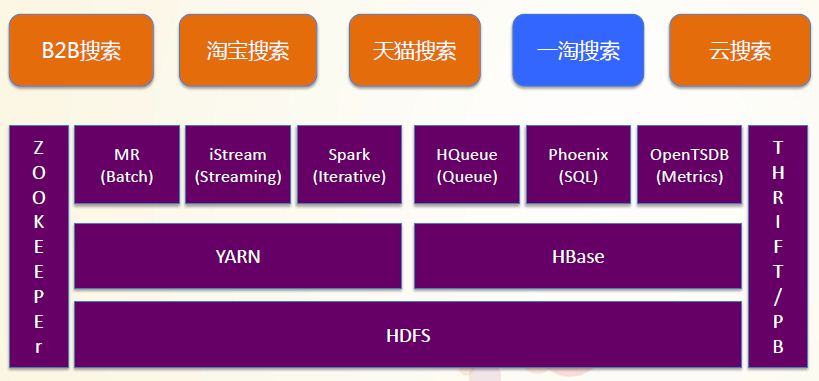
分析:
* 对于基于HBase的HQueue是一个创新,当前没有看到更多的资料,无法和Kafka对比。(在性能和TPC上可能Kafka更强大,但通过对HBase的复用做出Queue,很赞。)
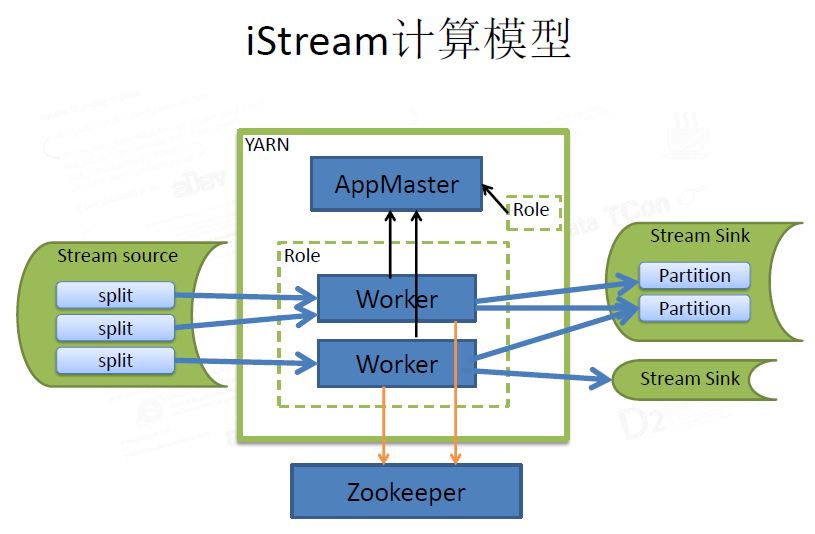
* iStream是一个Steaming on YARN的产品,从架构上看很类似storm的设计理念。
HBase
HBase应用
1. Phoenix(SQL on HBase)
2. OpenTSDB(Metrics on HBase)
3. HQueue(Queue on HBase)
分析:
* 在HBase集群上运行了Phoenix、OpenTSDB、HQueue三种应用,因此HBase具有作为一种数据存储的基础设施的能力。
HBase网页库存储方案
1. 版本从0.25、0.26、0.90、0.92、0.94、0.98逐步升级的。
2. HBase集群规模从30多台持续升级到300多台。
3. HBase Region个数从 1K 增长到 20K。
4. 网页数量从 十亿 增长到 百亿。
存储业务数据的CF如下: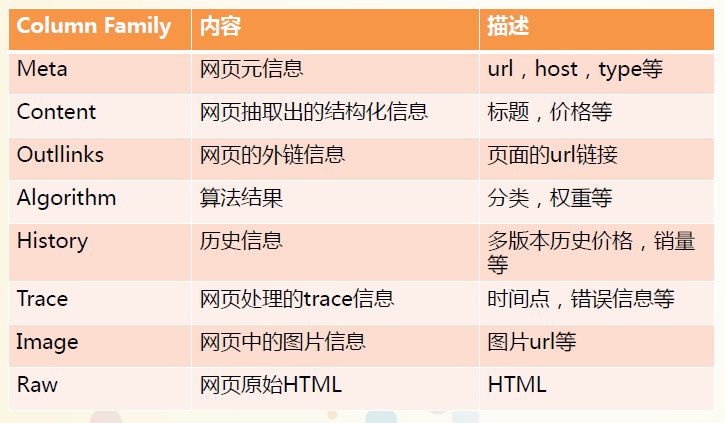
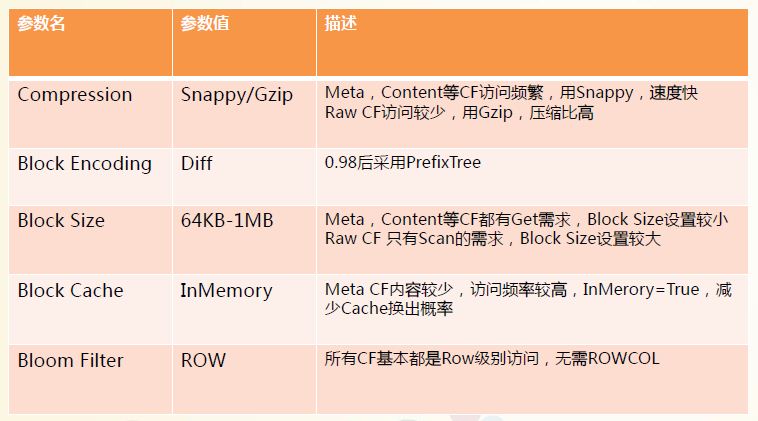
在HBase/Hadoop的I/O上的优化如下:
1. Compression:Snappy/Gzip
2. Block Encoding:Diff
3. Block Size:64KB - 1MB
4. Block Cache:InMemory
5. Bloom Filter:ROW
HBase Coprocessor应用
在网页库中使用了三种Coprocessor:
1. Trace Coprocessor
2. Clone Coprocessor
3. Incremental Coprocessor

分析:
* 如果HBase集群就是两个集群中的一个,那么裸存储容量最大为:12 * 2T * 300 = 7200T = 7.2P,如果考虑到压缩、复制因子、数据冗余、容量冗余,可以存储有效数据约为:8P 数据。
* 平均每台服务器运行的Region个数:20K/300 = 67 个,这个数字比较符合HBase官方推荐的值。
* Compression方法用了snappy和gzip两种。CF访问频繁,使用snappy,速度快;Raw CF访问较少,使用gzip,压缩比高。
* Block Encoding使用Diff,0.98后改用PrefixTree;
* Block Size的大小为 64KB - 1MB
实时处理架构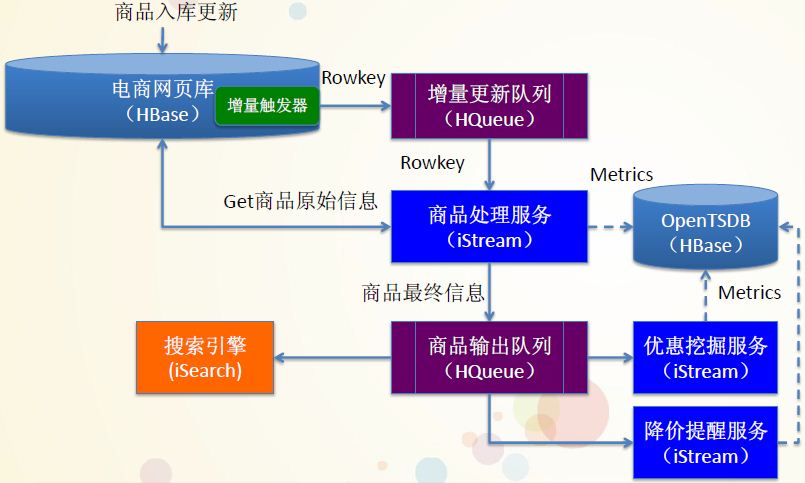
分析
* Metrics实时采集的流程大约是:HBase -> HQueue -> iStream -> OpenTSDB on HBase
* 流处理的全流程:HBase -> HQueue -> iStream -> HQueue -> iSearch/iStream
* 参见前文分析,猜测iStream是一个类似Storm的YARN框架。
关于阿里搜索自研的iStream的架构与文档参加如下: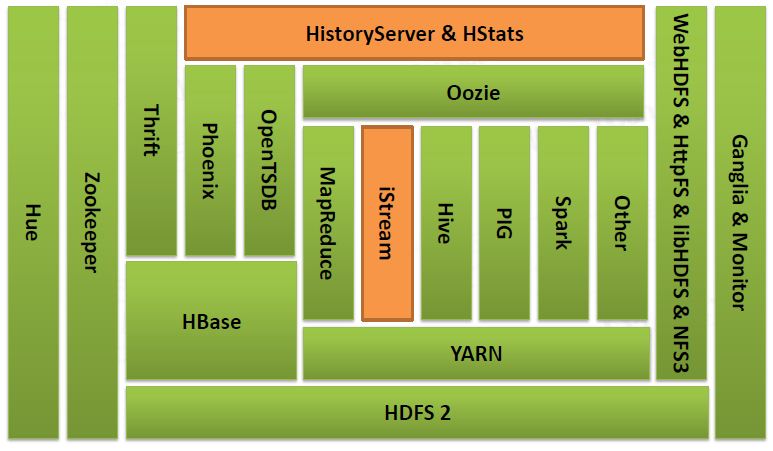
http://www.infoq.com/cn/news/2014/09/hadoop-alibaba-yarn
http://club.alibabatech.org/resource_detail.htm?topicId=140