七牛是如何搞定每天500亿条日志的 http://www.csdn.net/article/2015-07-30/2825342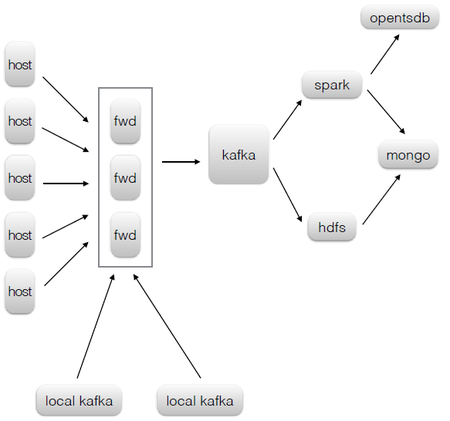
日志处理的大致分为三步:
1. 日志采集,主要是通过Agent和Flume;
2. 日志流转,主要是通过Kafka;
3. 日志计算,主要是通过Spark Streaming作为计算引擎;
大致的处理流程:
1. Agent/Local Kafka -> Flume -> Kafka -> HDFS -> mongoDB
2. Agent/Local Kafka -> Flume -> Kafka -> Spark -> mongoDB
3. Agent/Local Kafka -> Flume -> Kafka -> Spark -> opentsdb
流程3只是见于图上,文字上没有任何提到。
在日志采集中,通过Agent将业务应用和日志采集进行了分离,采取了Agent主动来拉的模式。专门强调了Agent 的设计需求:1
2每台机器上会有一个Agent去同步这些日志,这是个典型的队列模型,业务进程在不断的push,Agent在不停的pop。Agent需要有记忆功能,用来保存同步的位置(offset),这样才尽可能保证数据准确性,但不可能做到完全准确。由于发送数据和保存offset是两个动作,不具有事务性,不可避免的会出现数据不一致性情况,通常是发送成功后保存offset,那么在Agent异常退出或机器断电时可能会造成多余的数据。
在这里,Agent需要足够轻,这主要体现在运维和逻辑两个方面。Agent在每台机器上都会部署,运维成本、接入成本是需要考虑的。Agent不应该有解析日志、过滤、统计等动作,这些逻辑应该给数据消费者。倘若Agent有较多的逻辑,那它是不可完成的,不可避免的经常会有升级变更动作。
为什么Agent没有直接将日志发送给Kafka,而是通过Flume来做:1
2
3具体架构上,Agent并没把数据直接发送到Kafka,在Kafka前面有层由Flume构成的forward。这样做有两个原因:
1. Kafka的API对非JVM系的语言支持很不友好,forward对外提供更加通用的http接口。
2. forward层可以做路由、Kafka topic和Kafka partition key等逻辑,进一步减少Agent端的逻辑。
Kafka使用建议
1.Topic划分。尽量通过划分Topic分离不同类型的数据;
2.Kafka partition数目直接关系整体的吞吐量。3个Partition能够跑满一块磁盘的IO。
3.Partition key设计。partition key选择不当,可能会造成数据倾斜。在对数据有顺序性要求才需使用partition key。Kafka的producer sdk在没指定partition key时,在一定时间内只会往一个partition写数据,这种情况下当producer数少于partition数也会造成数据倾斜,可以提高producer数目来解决这个问题。
实时计算Spark Streaming
1.当前Spark只用作统计,没有进行迭代计算(DAG)。场景比较简单。
2.Spark Streaming从Kafka中读数据,统计完结果如mongoDB。可以理解是Spark Streaming + mongoDB的应用。
3.Spark Streaming对存储计算结果的数据库tps要求较高。比如有10万个域名需要统计流量,batch interval为10s,每个域名有4个相关统计项,算下来平均是4万 tps,考虑到峰值可能更高,固态硬盘上的mongo也只能抗1万tps,后续我们会考虑用redis来抗这么高的tps。难道Redis能够支持很高的TPS?
4.有状态的Task的挑战:有外部状态的task逻辑上不可重入的,当开启speculation参数时候,可能会造成计算的结果不准确。说个简单的例子。这个任务,如果被重做了,会造成落入mongo的结果比实际多。有状态的对象生命周期不好管理,这种对象不可能做到每个task都去new一个。我们的策略是一个JVM内一个对象,同时在代码层面做好并发控制。
七牛数据平台规模1
线上的规模:Flume + Kafka + Spark8台高配机器,日均500亿条数据,峰值80万tps。
因此,
1.如果是Flume/Kafka/Spark共享同一个物理集群,硬件压力如何?
2.如果每条日志 0.1K,那么每天总数据量 50G 0.1K = 5T,每个节点每秒 5T/243600/8 = 7.23M。
参考:
【微信分享】王团结:七牛是如何搞定每天500亿条日志的
http://www.csdn.net/article/2015-07-30/2825342
对七牛云存储日志处理的思考
http://hadoop1989.com/2015/08/02/Think-QiNiu-Cloud/