《腾讯在Spark上的应用与实践优化》原文参见:http://download.csdn.net/detail/happytofly/8637461
TDW: Tencent Distributed Data Warehouse,腾讯分布式数据仓库;
GAIA:腾讯自研的基于YARN定制化和优化的资源管理系统;
Lhoste:腾讯自研的作业的工作流调度系统,类似于Oozie;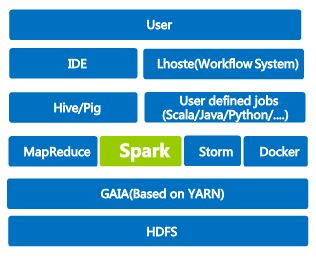
TDW集群规模:
1. Gaia集群节点数:8000+;
2. HDFS的存储空间:150PB+;
3. 每天新增数据:1PB+;
4. 每天任务数:1M+;
5. 每天计算量:10PB+;
Spark集群:
1. Spark部署在Gaia之上,即是Spark on YARN模式,每个节点是 24 cores 和 60G 内存;
2. 底层存储包括:HDFS、HBase、Hive、MySQL;
3. 作业类型,包括:ETL、SparkSQL、Machine Learning、Graph Compute、Streaming;
4. 每天任务数,10K+;
5. 腾讯从2013年开始引入Spark 0.6,已经使用2年了;
Spark的典型应用:
1. 预测用户的广告点击概率;
2. 计算两个好友间的共同好友数;
3. 用于ETL的SparkSQL和DAG任务;
Case 1: 预测用户的广告点击概率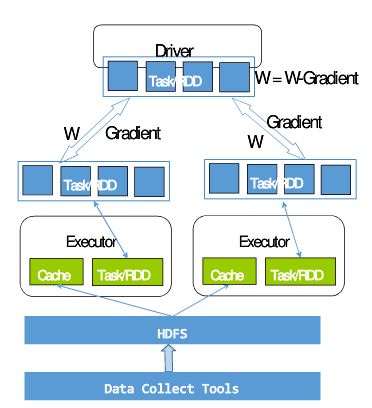
1. 数据是通过DCT(Data Collect Tool)推送到HDFS上,然后Spark直接将HDFS数据导入到 RDD&Cache;
2. 60次迭代计算的时间为10~15分钟,即每次迭代10~15秒;
Case 2: 计算两个好友间的共同好友数
1. 根据shuffle数量来确定partition数量;
2. 尽量使用sort-based shuffle,减少reduce的内存使用;
3. 当连接超时后选择重试来减少executor丢失的概率;
4. 避免executor被YARN给kill掉,设置 spark.yarn.executor.memoryoverhead
5. 执行语句 INSERT TABLE test_result SELECT t3.d, COUNT(*) FROM( SELECT DISTINCT a, b FROM join_1 ) t1 JOIN (SELECT DISTINCT b, c FROM join_2 ) t2 ON (t1.a = t2.c) JOIN (SELECT DISTINCT c, d FROM c, d FROM join_3 ) t3 ON (t2.b = t3.d) GROUP BY t3.d 使用Hive需要30分钟,使用SparkSQL需要5分钟;
6. 当有小表时使用broadcase join代替Common join;
7. 尽量使用ReduceByKey代替GroupByKey;
8. 设置spark.serializer = org.apache.spark.serializer.KryoSerializer;
9. 使用YARN时,设置spark.shuffle.service.enabled = true;
10. 在早期版本中Spark通过启动参数固定executor的数量,当前支持动态资源扩缩容特性
* spark.dynamicAllocation.enabled = true
* spark.dynamicAllocation.executorIdleTimeout = 120
* spark.dynamicAllocation.schedulerBacklogTimeout = 10
* spark.dynamicAllocation.minExecutors/maxExecutors
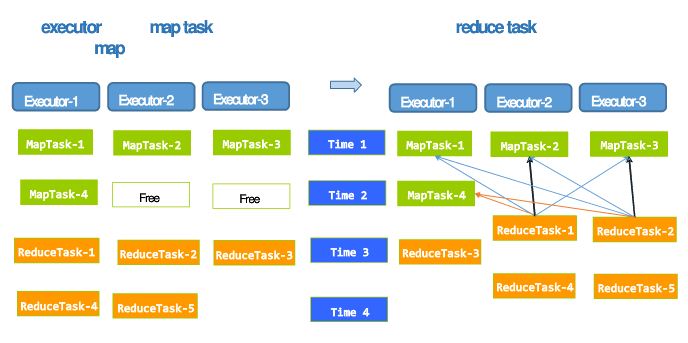
11. 当申请固定的executors时且task数大于executor数时,存在着资源的空闲状态。
<完>