Pinot:LinkedIn的实时数据分析系统
http://www.infoq.com/cn/news/2014/10/linkdln
https://engineering.linkedin.com/analytics/real-time-analytics-massive-scale-pinot
Twitter Heron:Twitter发布新的大数据实时分析系统Heron
http://geek.csdn.net/news/detail/33750
http://www.longda.us/?p=529
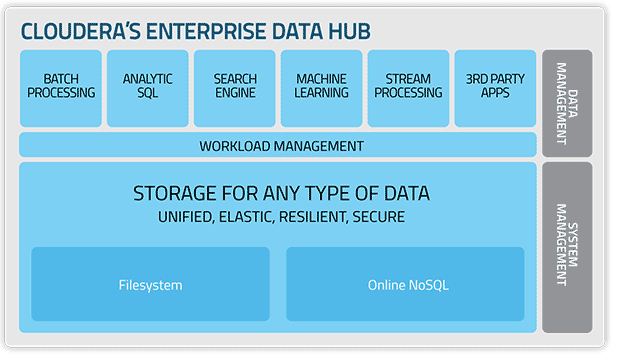
Cloudera
HBase对MOBs( Moderate Objects, 主要是大小100K到10M的对象存储 )的支持
http://blog.cloudera.com/blog/2015/06/inside-apache-hbases-new-support-for-mobs/
准实时计算架构模式
http://blog.cloudera.com/blog/2015/06/architectural-patterns-for-near-real-time-data-processing-with-apache-hadoop/
(翻译:http://zhuanlan.zhihu.com/donglaoshi/20082628 )
CDH 5.4 新功能:敏感数据处理(Sensitive Data Redaction)
http://blog.cloudera.com/blog/2015/06/new-in-cdh-5-4-sensitive-data-redaction/
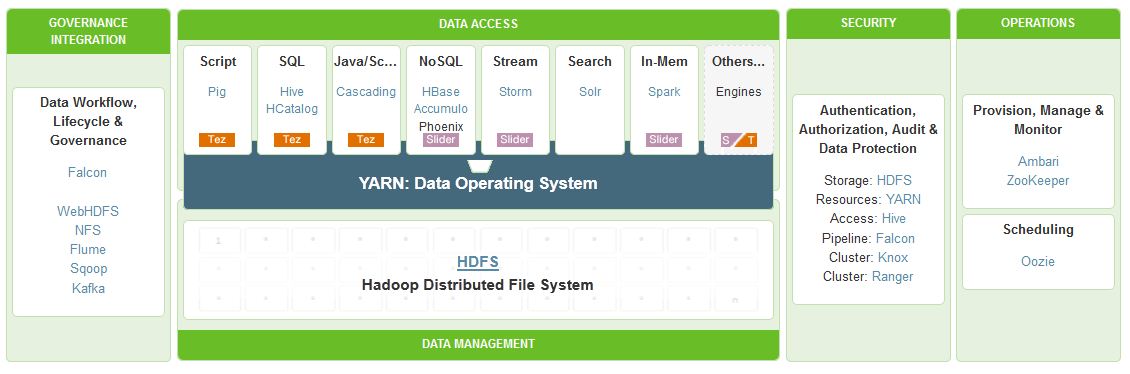
Hortonworks
YARN的CapacityScheduler对Resource-preemption的支持
http://hortonworks.com/blog/better-slas-via-resource-preemption-in-yarns-capacityscheduler/
Hadoop集群对Multihoming的支持
http://hortonworks.com/blog/multihoming-on-hadoop-yarn-clusters/
HDP 2.3企业级HDFS数据加密
http://hortonworks.com/blog/new-in-hdp-2-3-enterprise-grade-hdfs-data-at-rest-encryption/
Apache Slider 0.80.0版本发布
http://hortonworks.com/blog/announcing-apache-slider-0-80-0/
Apache Spark 1.3.1 on HDP 2.2
http://hortonworks.com/blog/apache-spark-on-hdp-learn-try-and-do/
http://hortonworks.com/hadoop-tutorial/using-apache-spark-technical-preview-with-hdp-2-2/
Ambari 2.0.1 和 HDP 2.2.6 发布
http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.2.6/bk_HDP_RelNotes/content/ch_relnotes_v226.html
http://docs.hortonworks.com/HDPDocuments/Ambari-2.0.1.0/bk_releasenotes_ambari_2.0.1.0/content/ch_relnotes-ambari-2.0.1.0.html
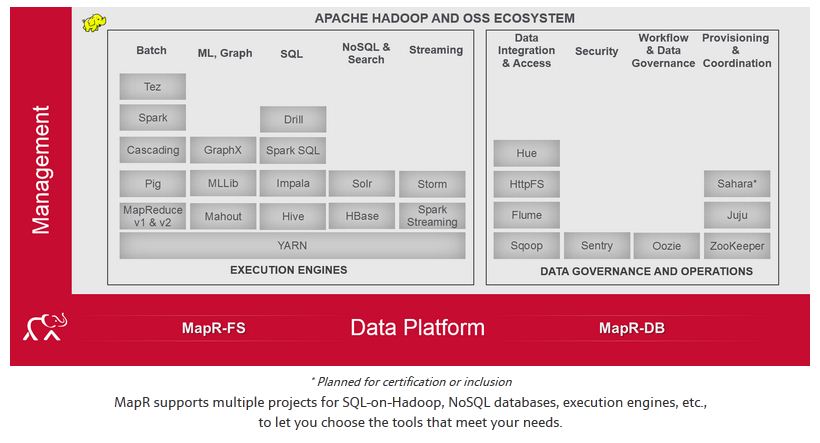
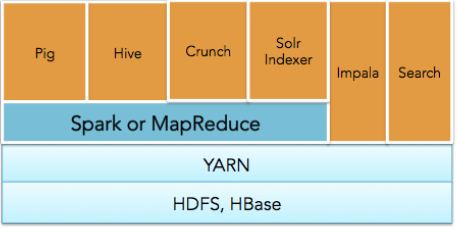
其他:
Graphite的百万Metrics实践之路
http://calvin1978.blogcn.com/articles/graphite.html
HBaseCon 2015 大会幻灯片 & 视频
http://hbasecon.com/archive.html
HBase在腾讯大数据的应用实践
http://www.d1net.com/bigdata/news/353500.html
从Spark到Hadoop的架构实践
http://www.csdn.net/article/2015-06-08/2824889
56网大数据
http://share.csdn.net/slides/10903
七牛技术总监陈超:记Spark Summit China 2015
http://www.csdn.net/article/2015-04-30/2824594-spark-summit-china-2015
唯品会美研中心郭安琪:2015 Hadoop Summit见闻
http://zhuanlan.zhihu.com/donglaoshi/20072576
华为叶琪:论Spark Streaming的数据可靠性和一致性
http://www.csdn.net/article/2015-06-12/2824938
Hadoop Summit 2015
http://2015.hadoopsummit.org/san-jose/agenda/
Spark Summit 2015
https://spark-summit.org/2015/