原文:http://hortonworks.com/blog/impala-vs-hive-performance-benchmark/
学习如下:
本文是Yahoo! JAPAN针对自己的场景需求进行设计书选型,对Impala和Hive(Tez on YARN)所做的评测。
场景数据和要求:
- 数据格式为 Text 或者 gz ;
- 每天新增数据文件为10G,数据记录为13亿行;
- 数据留存(retention)周期为13个月,共有数据6000G,共有4500亿行;
- 每个小时需要生成 15000 个报表(reporting);
- 查询条件包含少量的的 grouping ,grouping的条件主要是地区(region)或者性别(gender);
- 没有过滤条件查询;
- 绝大部分基于时间的报表(report)生成都是周期性的,除了小时报表,还有天报表和周报表;
技术选型:
- Cloudera Impala,没提到所评估的版本,估计为最近的版本。当前Impala的最新版本为。
- Hortonworks HDP 2.2, Apache Hive-0.14, Apache Tez。
考虑Impala
- Imapa查询耗时比较少,一般在几秒到几十秒之间;
- 当一次查询的响应时间为15秒,每小时能够执行240次查询;
- 针对单位时间内处理量的不断增加,需要考虑通过增加单位时间内的并行查询数量来提升查询的数量;使用Impala遇到的问题是,随着查询并行度的增加,Impala查询的响应时间线性增加;因此,在每天数据更新之后Impala无法自动处理完成所有的批量查询。
考虑Hive和Tez on YARN
Hadoop-2.x, YARN有更好粒度的并行执行控制,Tez引擎能大幅度的降低MapReduce的延时。
YARN和Tez大幅度的增加处理能力,每小时需要处理超过15000个任务。之前的Hadoop 1.0集群,每天已经能够处理100000个任务。
测试验证
测试条件
- 计划模拟真实业务场景测试执行近2000个SQL;
- 绝大部分查询返回的结果少于 1000 行数据;
- 少数查询返回的结果超过100000行数据;
- 执行近2000个SQL的并发请求为32;
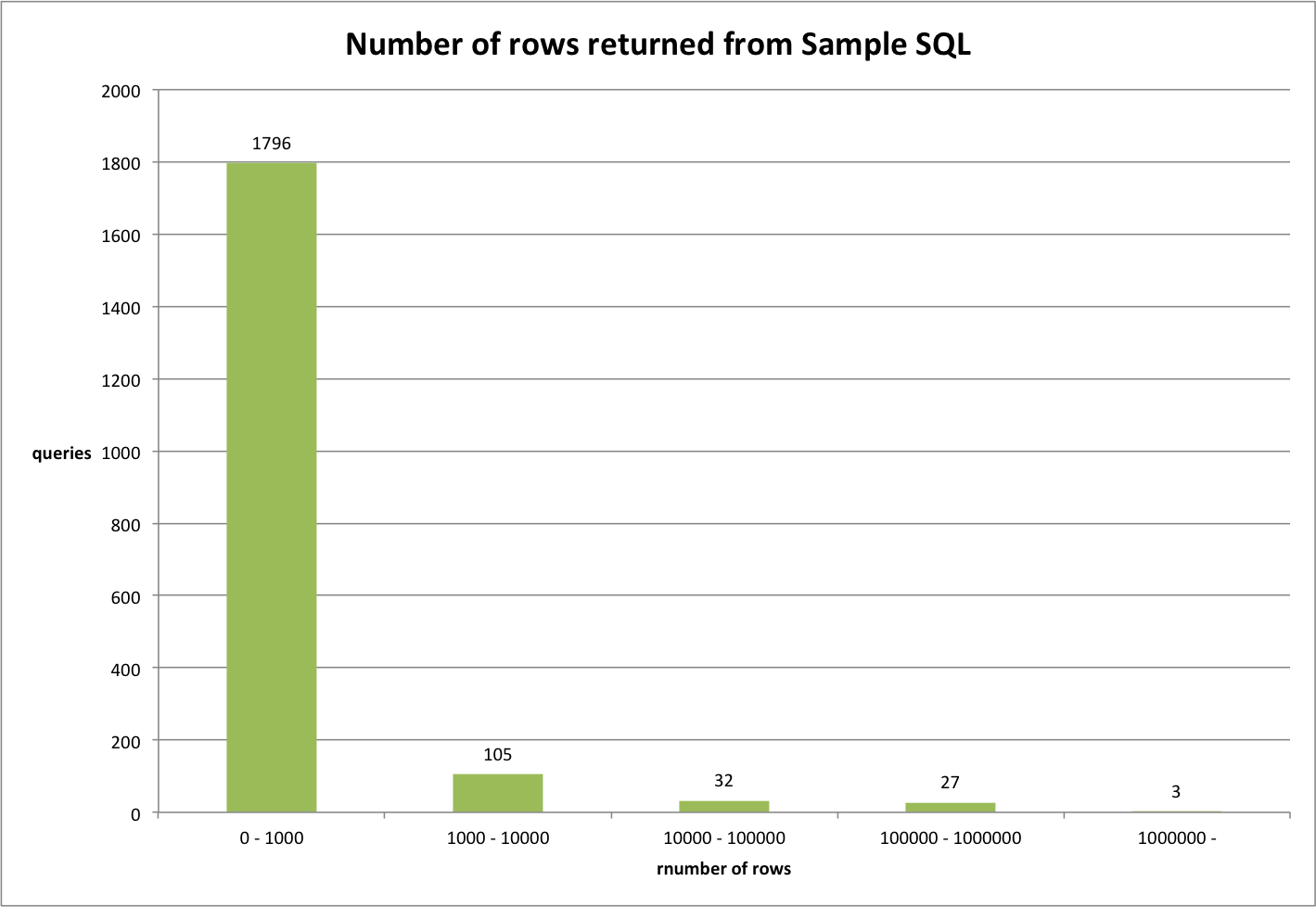
测试结果
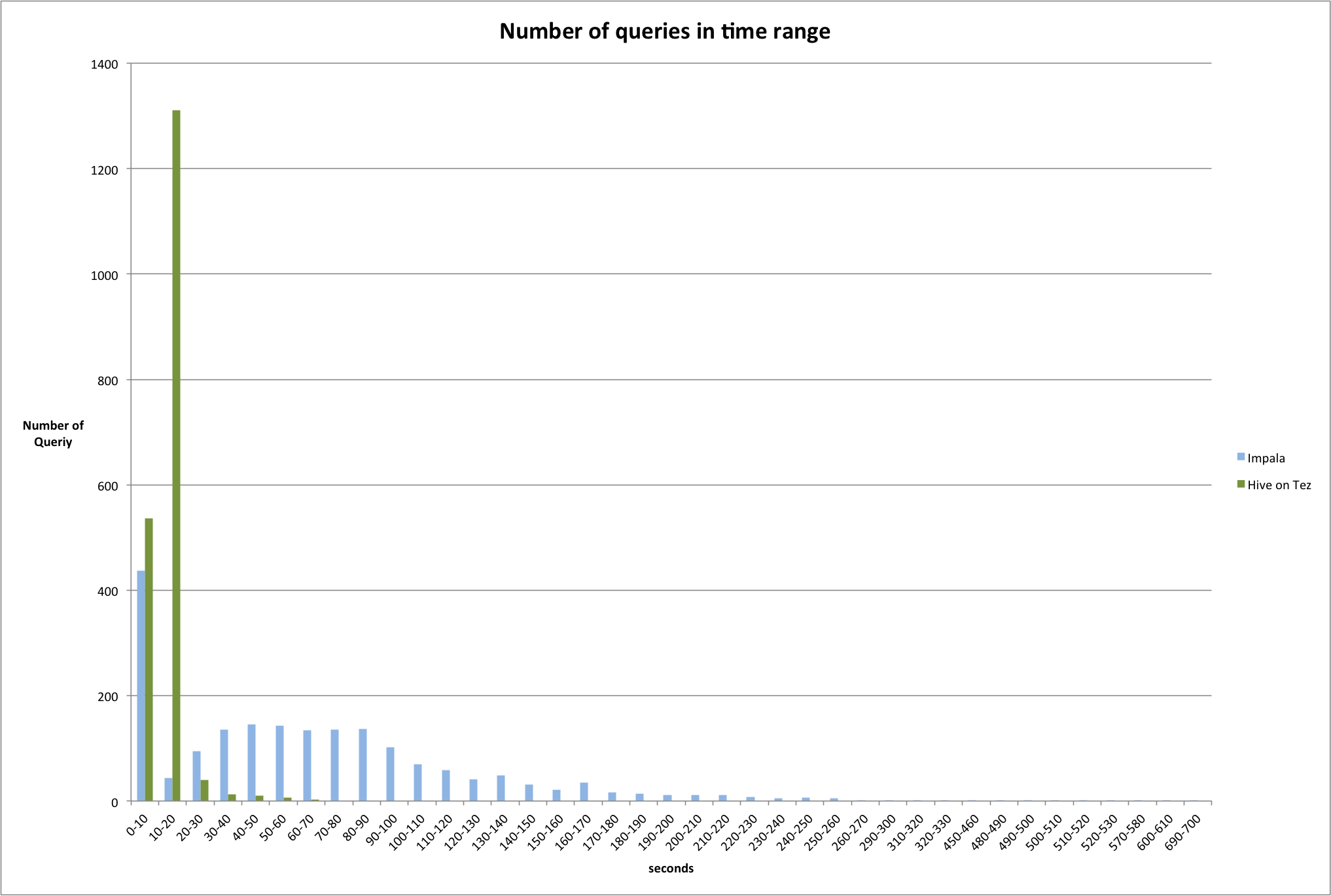
- Hive请求的大部分请求在20秒以内返回,随着返回结果集数据的增加查询时间也随之增加,最长返回时间为70秒;
- Impala请求的大部分请求返回在30秒~60秒之间,最长返回时间为10分钟,随着返回结果集数据的增加查询时间大幅度显著的增加;
- 在一些低负载(low load)条件的查询中,Impala能够达到毫秒(milliseconds)级返回;如果没有SQL并行化的处理需求,Impala是有效的选择。
- 对于要求批处理,并且SQL并行化是必须的场景中,Hive on Tez是更好的选择。
Hive的并发性
对于单个的HiveServer2实例,我们测试验证多少个并行查询可以被执行,多少并行度的处理是最有效的。
我们以16作为SQL并发执行的提升倍数,衡量的指标是SQL执行的处理时间。
在并发达到64之前查询的吞吐量快速增加,在这点之后开始下降,因此在当前环境下64是最好的并发数。
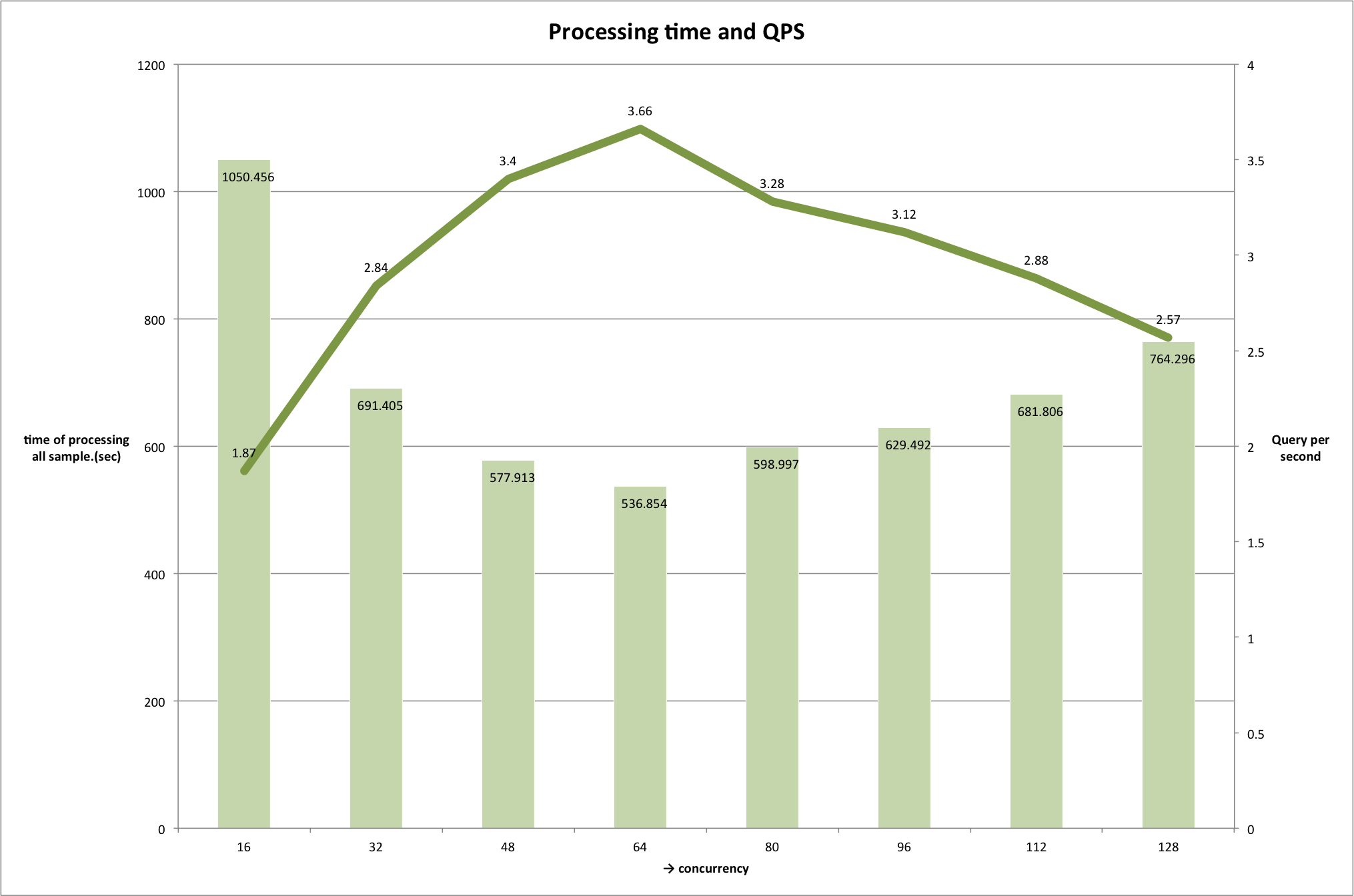
结论
对于Hive on Tez,单个SQL执行时间一般为15秒,会随着并行度的提升而增加。(并行度的限制主要依赖于集群的大小和性能。)
在低负载状态下Impala有非常快的响应时间,但并不适合于SQL并行度非常高的场景。
最后的结论是测试者最后选择了Hive on Tez,因为测试者的场景是每小时至少处理15000个SQL请求。