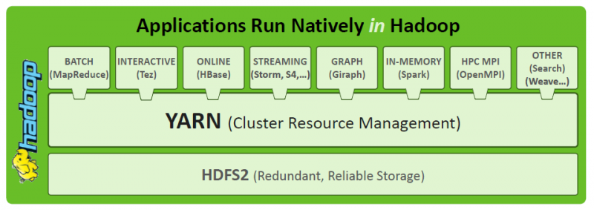
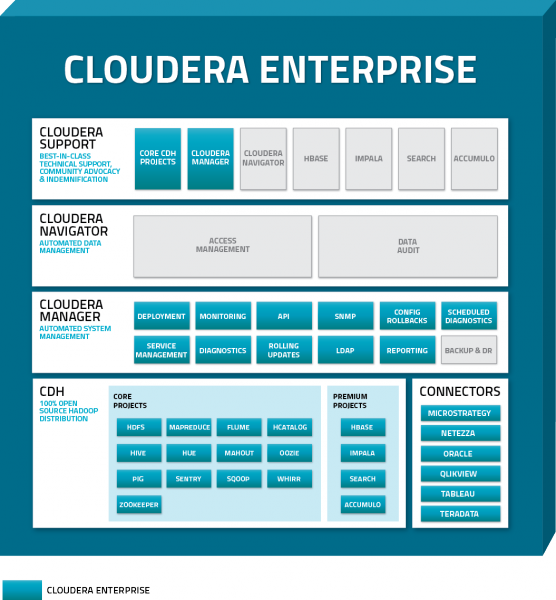
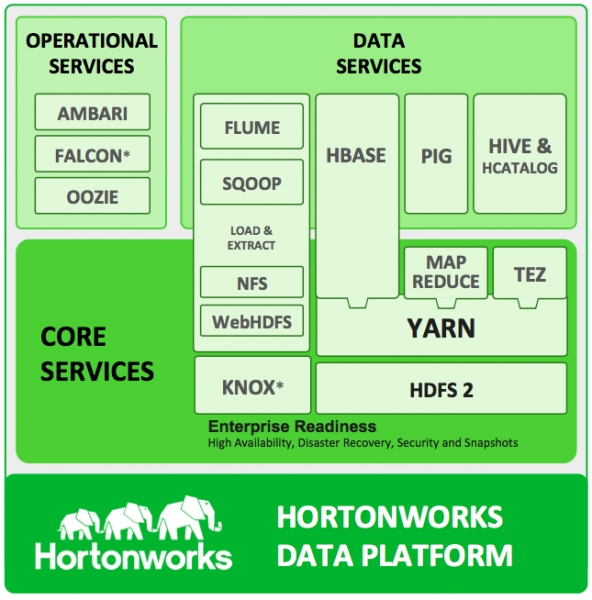
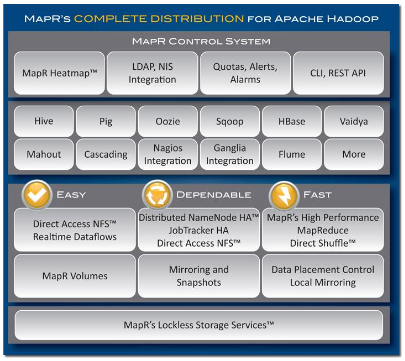
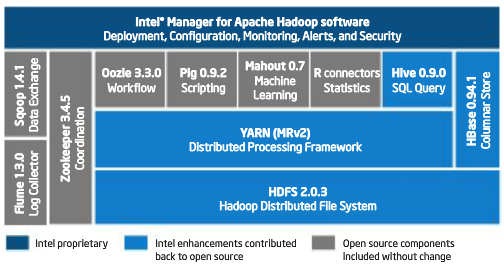
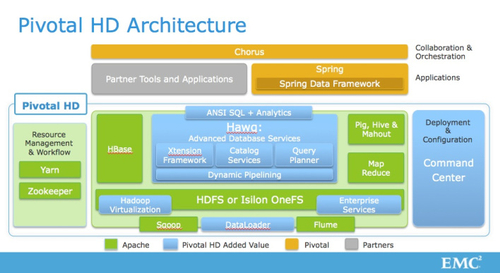
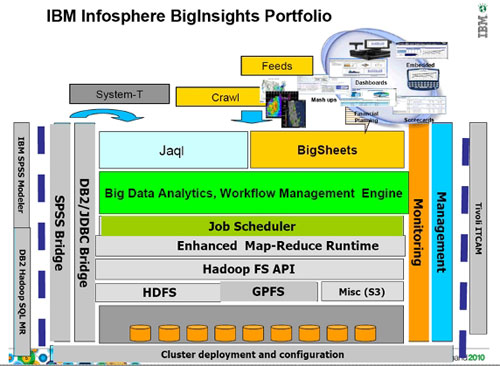
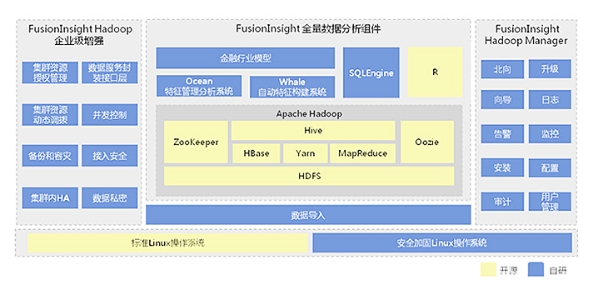
环境:
1. Windows XP
2. Git
步骤:
1. 安装Node.js
2. 安装Hexo
3. 创建博客(初始化Hexo)
4. 创建文章本地调试
5. 配置Github
6. 远程发布
7. 支持sitemap和feed
8. 支持百度统计
9. 支持图片
10. 支持Swiftype站内搜索
11. 参考资源
安装Node.js 下载并安装,https://nodejs.org/
安装Hexo 通过命令 npm install -g hexo 安装
D :\git\hexo>npm install -g hexo
npm WARN optional dep failed, continuing fsevents@0 .3.6
npm WARN optional dep failed, continuing fsevents@0 .3.6
-
> dtrace-provider@0 .5.0 install C :\Users\stevenxu\AppData\Roaming\npm\node_modules\hexo\node_modules\bunyan\node_modules\dtrace-provider
> node scripts/install.js
C :\Users\stevenxu\AppData\Roaming\npm\hexo -> C :\Users\stevenxu\AppData\Roaming\npm\node_modules\hexo\bin\hexo
hexo@3 .1.1 C :\Users\stevenxu\AppData\Roaming\npm\node_modules\hexo
├── pretty-hrtime@1 .0.0
├── hexo-front-matter@0 .2.2
├── abbrev@1 .0.7
├── titlecase@1 .0.2
├── archy@1 .0.0
├── text-table@0 .2.0
├── tildify@1 .1.0 (os-homedir@1 .0.1 )
├── strip-indent@1 .0.1 (get-stdin@4 .0.1 )
├── hexo-i18n@0 .2.1 (sprintf-js@1 .0.3 )
├── chalk@1 .1.0 (escape-string-regexp@1 .0.3 , supports-color@2 .0.0 , ansi-styles@2 .1.0 , strip-ansi@3 .0.0 , has-ansi@2 .0.0 )
├── bluebird@2 .9.34
├── minimatch@2 .0.10 (brace-expansion@1 .1.0 )
├── through2@1 .1.1 (xtend@4 .0.0 , readable-stream@1 .1.13 )
├── swig-extras@0 .0.1 (markdown@0 .5.0 )
├── hexo-fs@0 .1.3 (escape-string-regexp@1 .0.3 , graceful-fs@3 .0.8 , chokidar@0 .12.6 )
├── js-yaml@3 .3.1 (esprima@2 .2.0 , argparse@1 .0.2 )
├── nunjucks@1 .3.4 (optimist@0 .6.1 , chokidar@0 .12.6 )
├── warehouse@1 .0.2 (graceful-fs@3 .0.8 , cuid@1 .2.5 , JSONStream@0 .10.0 )
├── cheerio@0 .19.0 (entities@1 .1.1 , dom-serializer@0 .1.0 , css-select@1 .0.0 , htmlparser2@3 .8.3 )
├── bunyan@1 .4.0 (safe-json-stringify@1 .0.3 , dtrace-provider@0 .5.0 , mv@2 .1.1 )
├── hexo-cli@0 .1.7 (minimist@1 .1.2 )
├── moment-timezone@0 .3.1
├── moment@2 .10.3
├── hexo-util@0 .1.7 (ent@2 .2.0 , highlight.js@8 .6.0 )
├── swig@1 .4.2 (optimist@0 .6.1 , uglify-js@2 .4.24 )
└── lodash@3 .10.0
D :\git\hexo>
创建博客(初始化hexo) 创建博客站点的本地目录,然后在文件夹下执行命令:
$ hexo init
[info] Copying datanpm install before you start b
Hexo会自动在目标文件夹下建立网站所需要的文件。然后按照提示,安装node_modules,执行如下命令:
$ hexo install
创建文章本地调试 预览本地调试模式,执行如下命令:
$ hexo server
[info] Hexo is running at http://localhost:4000/ . Press Ctrl+C to stop.
关键命令简介:
hexo n
hexo g
hexo s
hexo d
创建文章
$ hexo new "使用Hexo搭建Github静态博客"
在Hexo工作文件夹下source_posts发现新创建的md文件 使用Hexo搭建Github静态博客.md 。
配置Github 部署到Github需要修改配置文件_config.yml文件,在Hexo工作目录之下:
# Deployment
## Docs: http:
deploy:
type: git
repository: git@github .com: <Your Github Username>/<Your github.io url>
branch: master
注意,当前type为git,而不是github
测试Github是否好用
ssh -T git@github .com
远程发布 远程部署到Github,通过执行如下命令:
$ hexi deploy
Troubleshootinghttp://blog.csdn.net/rainloving/article/details/46595559
使用github出现:fatal: unable to access: Failed connect to github.com:8080: No errorhttp://www.zhihu.com/question/26954892
使用github出现:ssh:connect to host github.com port 22: Bad file numberhttp://www.xnbing.org/?p=759 http://blog.csdn.net/temotemo/article/details/7641883
支持sitemap和feed 首先安装sitemap和feed插件
$ npm install hexo-generator-sitemap
$ npm install hexo-generator-feed
修改配置,在文件 _config.yml 增加以下内容
# Extensions
Plugins:
- hexo-generator-feed
- hexo-generator-sitemap
#Feed Atom
feed:
type: atom
path: atom.xml
limit: 20
#sitemap
sitemap:
path: sitemap.xml
在 themes\landscape_config.yml 中添加:
menu :
Home : /
Archives : /archives
Sitemap : /sitemap.xml
rss : /atom.xml
支持百度统计 在 http://tongji.baidu.com 注册帐号,添加网站,生成统计功能的 JS 代码。
在 themes\landscape_config.yml 中新添加一行:
baidu_t ongji: true
在 themes\landscape\layout_partial\head.ejs 中head的结束标签 之前新添加一行代码
<% - partial % >
在 themes\landscape\layout_partial 中新创建一个文件 baidu_tongji.ejs 并添加如下内容:
if (theme.baidu_tongji){ %>
<script type ="text/javascript" >
<百度统计的 JS 代码>
</script >
<% } %>添加统计,参考:http://ibruce.info/2013/11/22/hexo-your-blog/ http://www.cnblogs.com/zhcncn/p/4097881.html
支持图片 在source目录下创建images目录,然后将图片放在其中。

支持swiftype站内搜索 在 http://siftype.com 注册一个帐号,按着网站引导流程就可以了。
Installation successfully activated
添加robots.txt http://blog.lmintlcx.com/post/blog-with-hexo.html
支持多说评论 首先,在多说官网 http://www.duoshuo.com 激活账户,并添加网站配置;http://dev.duoshuo.com/threads/541d3b2b40b5abcd2e4df0e9
duoshuo_shortname : 你站点的short_name
第二步修改themes\landscape\layout_partial\article.ejs模板,用多说推荐的代码替换之前的Disqus代码。1 2 3 4 5 6 7 if (!index && post.comments && config.disqus_shortname){ %><section id ="comments" > <div id ="disqus_thread" > <noscript > Please enable JavaScript to view the <a href ="//disqus.com/?ref_noscript" > comments powered by Disqus.</a > </noscript > </div > </section > } %>
改为1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <% if (!index && post.comments && config.duoshuo_shortname ){ %> <section id ="comments" > <div class ="ds-thread" data-thread-key ="<%= post.layout %>-<%= post.slug %>" data-title ="<%= post.title %>" data-url ="<%= page.permalink %>" > </div > <script type ="text/javascript" > var duoshuoQuery = {short_name:'<%= config.duoshuo_shortname %>' }; (function ( var ds = document .createElement('script' ); ds.type = 'text/javascript' ;ds.async = true ; ds.src = (document .location.protocol == 'https:' ? 'https:' : 'http:' ) + '//static.duoshuo.com/embed.js' ; ds.charset = 'UTF-8' ; (document .getElementsByTagName('head' )[0 ] || document .getElementsByTagName('body' )[0 ]).appendChild(ds); })(); </script > </section > <% } %>
参考资源 http://blog.lmintlcx.com/post/blog-with-hexo.html https://github.com/bruce-sha http://zipperary.com/2013/05/28/hexo-guide-2/ http://zipperary.com/2013/05/29/hexo-guide-3/ http://zipperary.com/2013/05/30/hexo-guide-4/ http://cnfeat.com/2014/05/10/2014-05-11-how-to-build-a-blog/ http://www.cnblogs.com/zhcncn/p/4097881.html http://blog.moyizhou.cn/web/search-engine-for-static-pages/ http://www.jerryfu.net/post/search-engine-for-hexo-with-swiftype.html