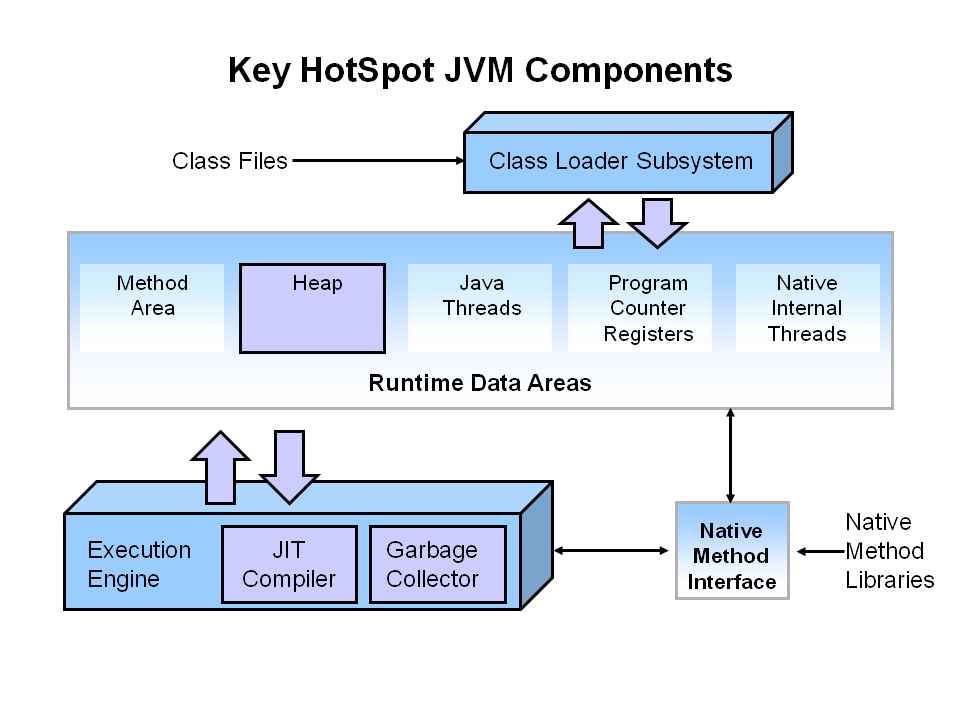
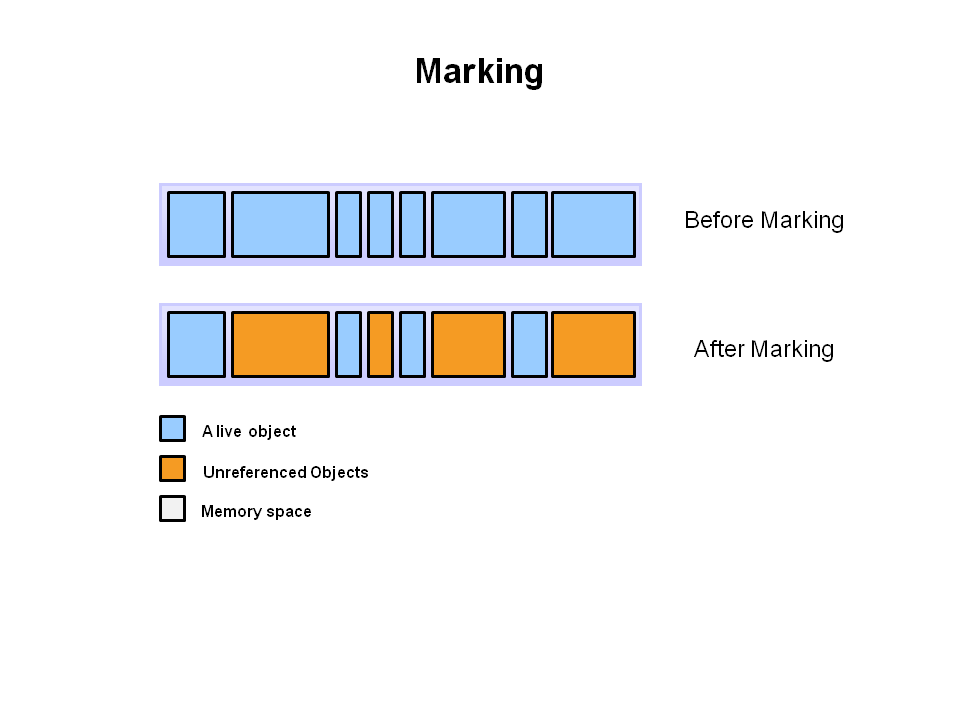
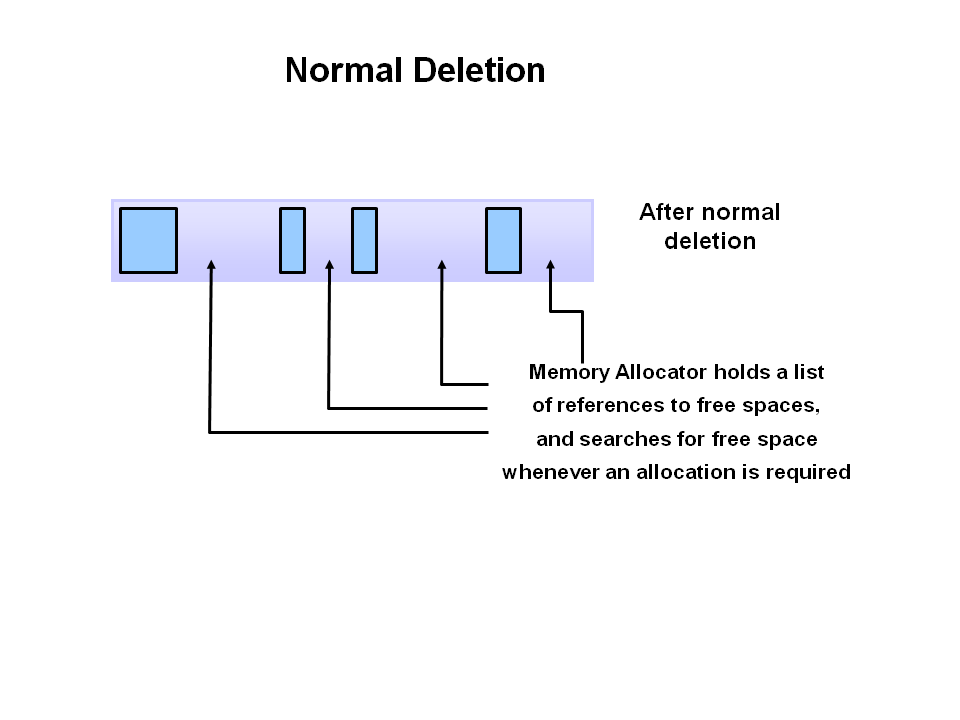
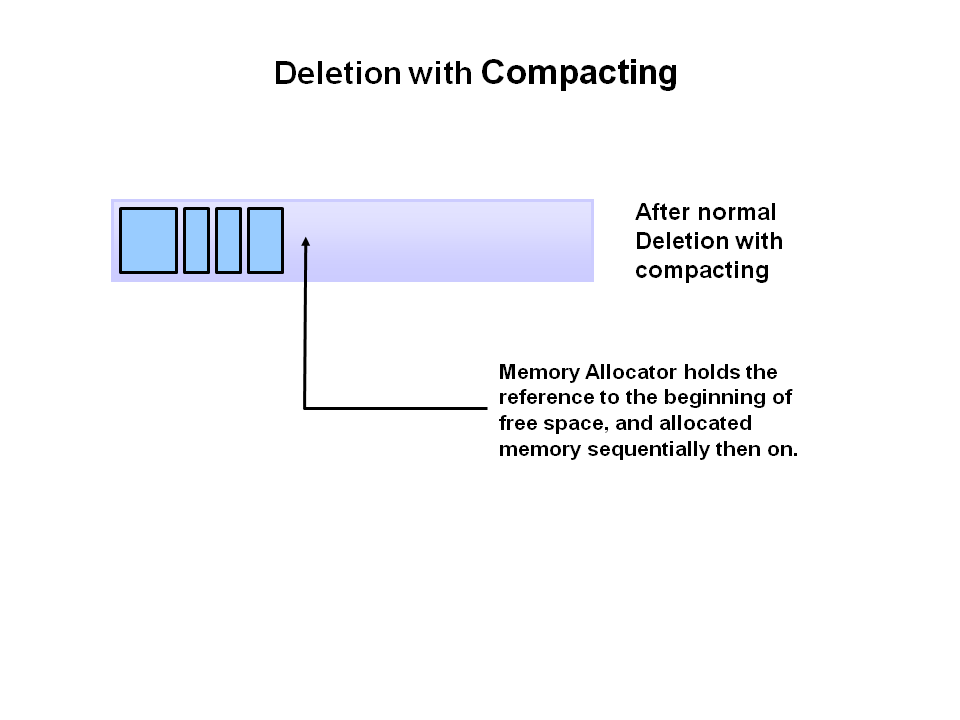
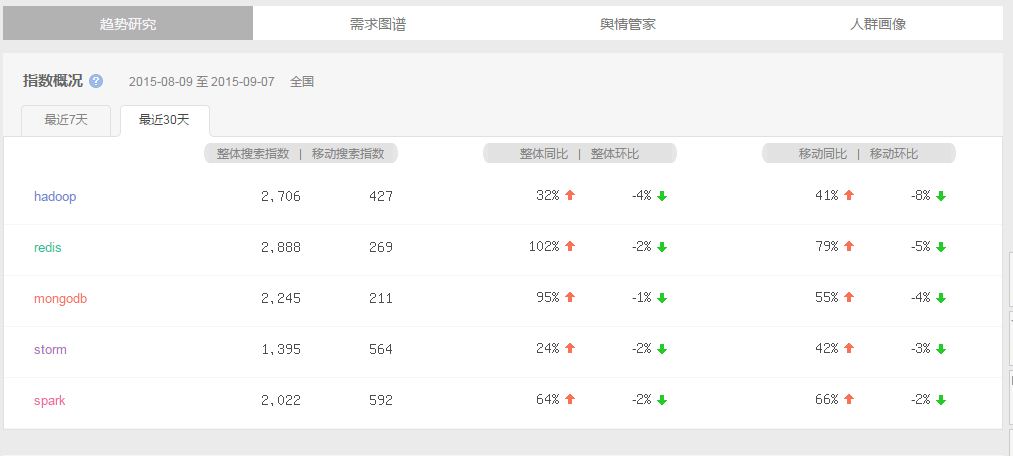
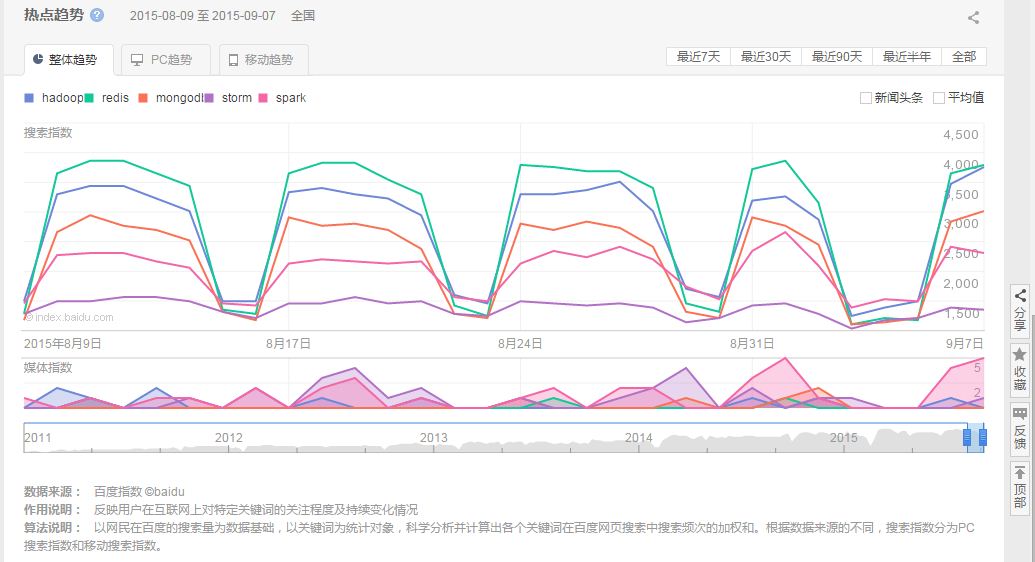
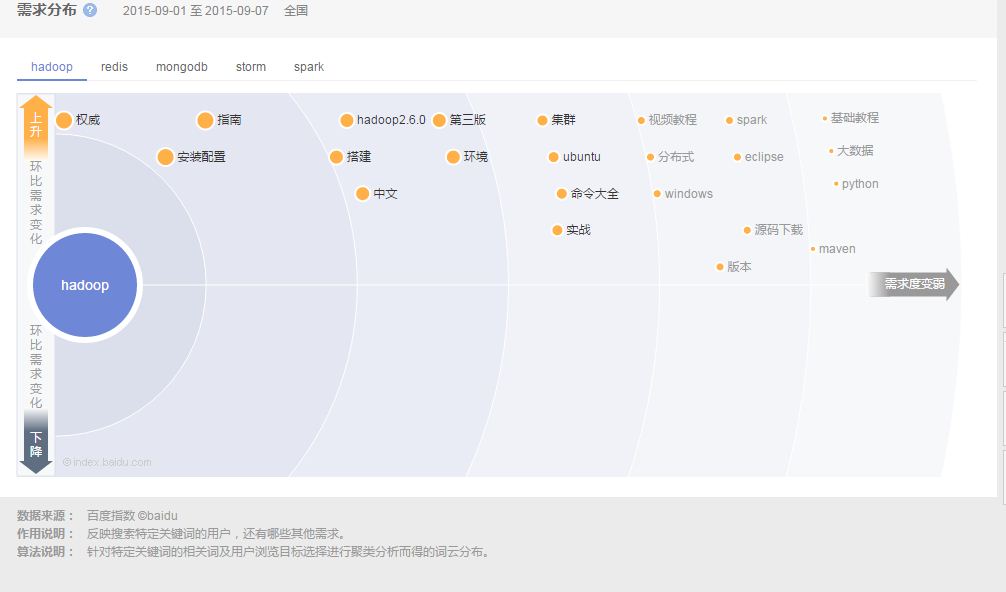
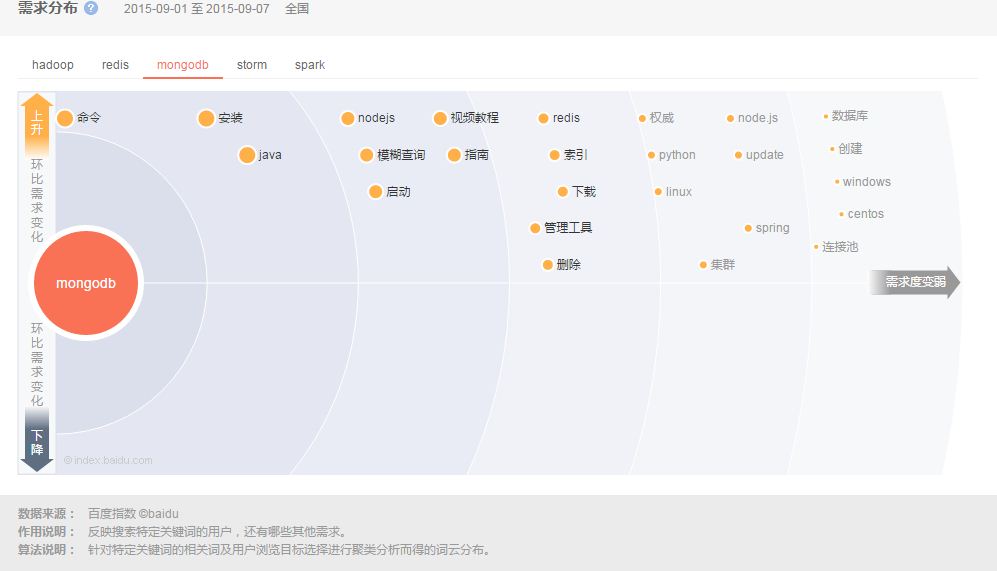
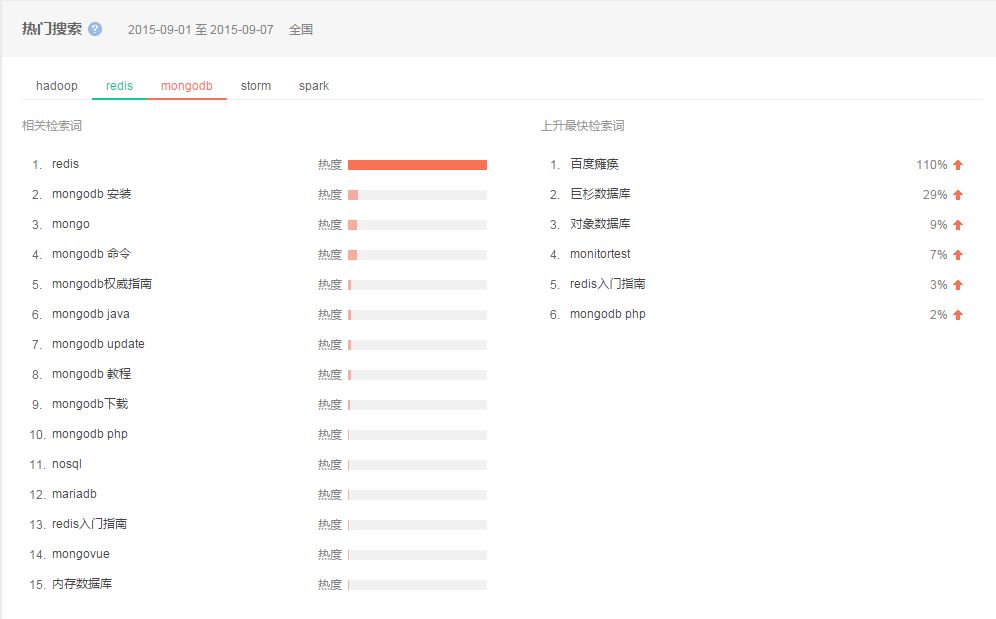
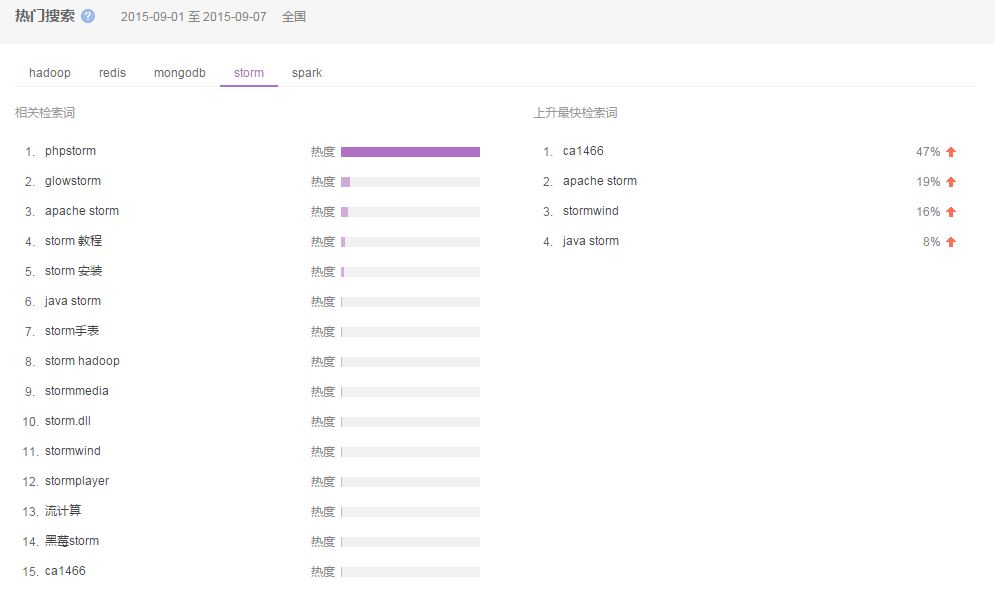
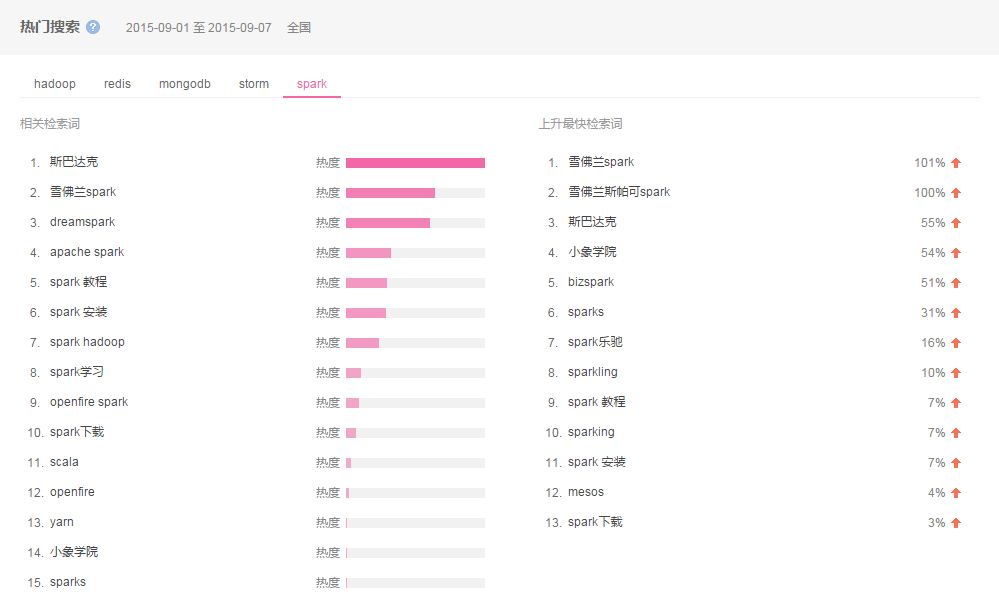
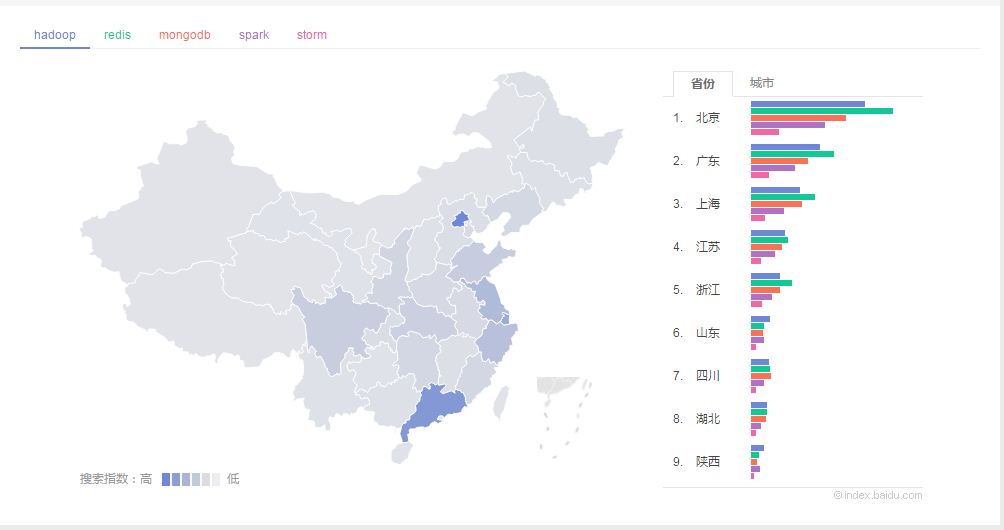
压缩,Deletion with Compacting 为了更好的性能,需要对不可回收依然使用的对象进行压缩,就是把这一类对象迁移在一起,使得新内存的分配变得的更容易和更快。
分代垃圾回收(Generational Garbage Collection)
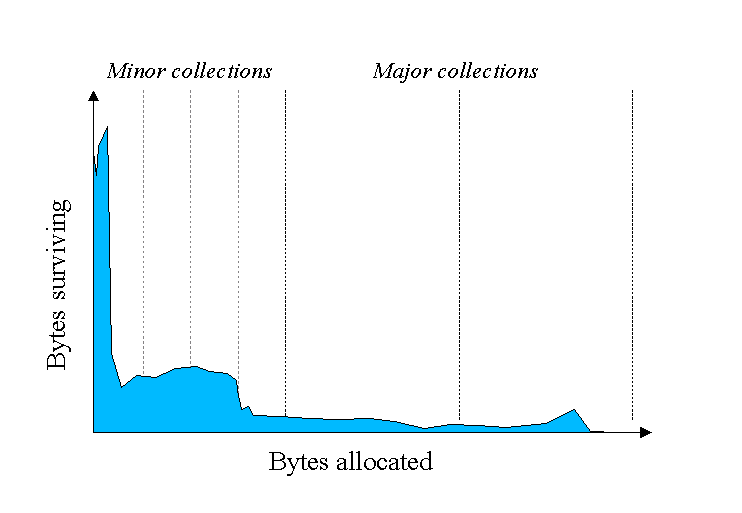
由于标记和压缩堆内存中所有的对象是十分低效的,并且随着越来越多的对象被分配,垃圾回收的时间也会变得越来越长,因此引入引入了如下的回收策略:按着对象存活的时间窗口采用不同的垃圾回收机制,即是 Minor collections 和 Major collections。如下图: 其中Y轴标识已分配的字节数,X轴标识随着时间已经被分配内存并且处于使用状态的字节数的情况。从这张图可以看出,只有很少的对象能够长时间需要保留下来,大部分对象只有很短的生命周期。
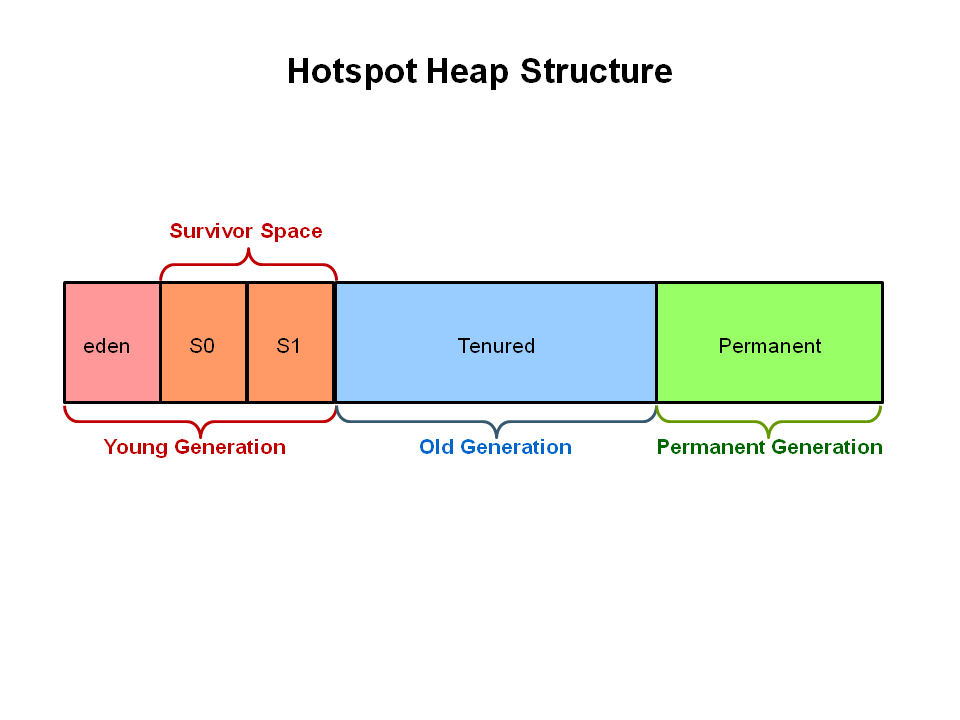
年轻代,Young Generation:分为三个区,一个Eden区,两个Survivor区。新生代主要是存放新生成的Java对象,新生代的垃圾回收称为 minor garbage collection。
年老代,Old Genration: 即是Tenured区,存放在年轻代经过多次垃圾回收依然存活的对象的区域,年老代的垃圾回收称为 major garbage collection。
垃圾回收触发时机
Minor Collection 在Eden空间已满,新对象申请空间失败时,就会触发Minor Collection,对Eden区域进行GC,清除非存活对象,并把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。这种方式的GC是对年轻代的Eden区进行,不会影响到年老代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden去能尽快空闲出来。
Major Collection(Full GC) 对整个堆进行整理,包括Young、Tenured和Perm。Major Collection因为需要对整个对进行回收,所以比Minor Collection要慢,因此应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于Major Collection的调节。有如下原因可能导致Full GC:
年老代(Tenured)被写满;
持久代(Perm)被写满;
System.gc()被显示调用;
上一次GC之后Heap的各域分配策略动态变化;
Garbage Collector
经过发展,Java已有如下的垃圾回收器:
Serial收集器/SerialOld收集器 Serial收集器/Serial Old收集器,是单线程的,使用“复制”算法。当它工作时,必须暂停其它所有工作线程。特点:简单而高效。对于运行在Client模式下的虚拟机来说是一个很好的选择。 串行收集器并不是只能使用一个CPU进行收集,而是当JVM需要进行垃圾回收的时候,需要中断所有的用户线程,知道它回收结束为止,因此又号称“Stop The World” 的垃圾回收器。 Serial收集器默认新旧生代的回收器搭配为Serial+ SerialOld
ParNew收集器 ParNew收集器其实就是多线程版本的Serial收集器,同样有 Stop The World的问题,他是多CPU模式下的首选回收器(该回收器在单CPU的环境下回收效率远远低于Serial收集器,所以一定要注意场景哦),也是Server模式下默认的新生代收集器。除了Serial收集器外,目前只有它能与CMS收集器配合工作。
CMS CMS(Concurrent Mark Sweep))又称响应时间优先(最短回收停顿)的回收器,使用并发模式回收垃圾,使用”标记-清除“算法,CMS对CPU是非常敏感的,它的回收线程数=(CPU+3)/4,因此当CPU是2核的实惠,回收线程将占用的CPU资源的50%,而当CPU核心数为4时仅占用25%。 CMS收集器分4个步骤进行垃圾收集工作: a. 初始标记(CMS initial mark) b. 并发标记(CMS concurrent mark) c. 重新标记(CMS remark) d. 并发清除(CMS concurrent sweep)
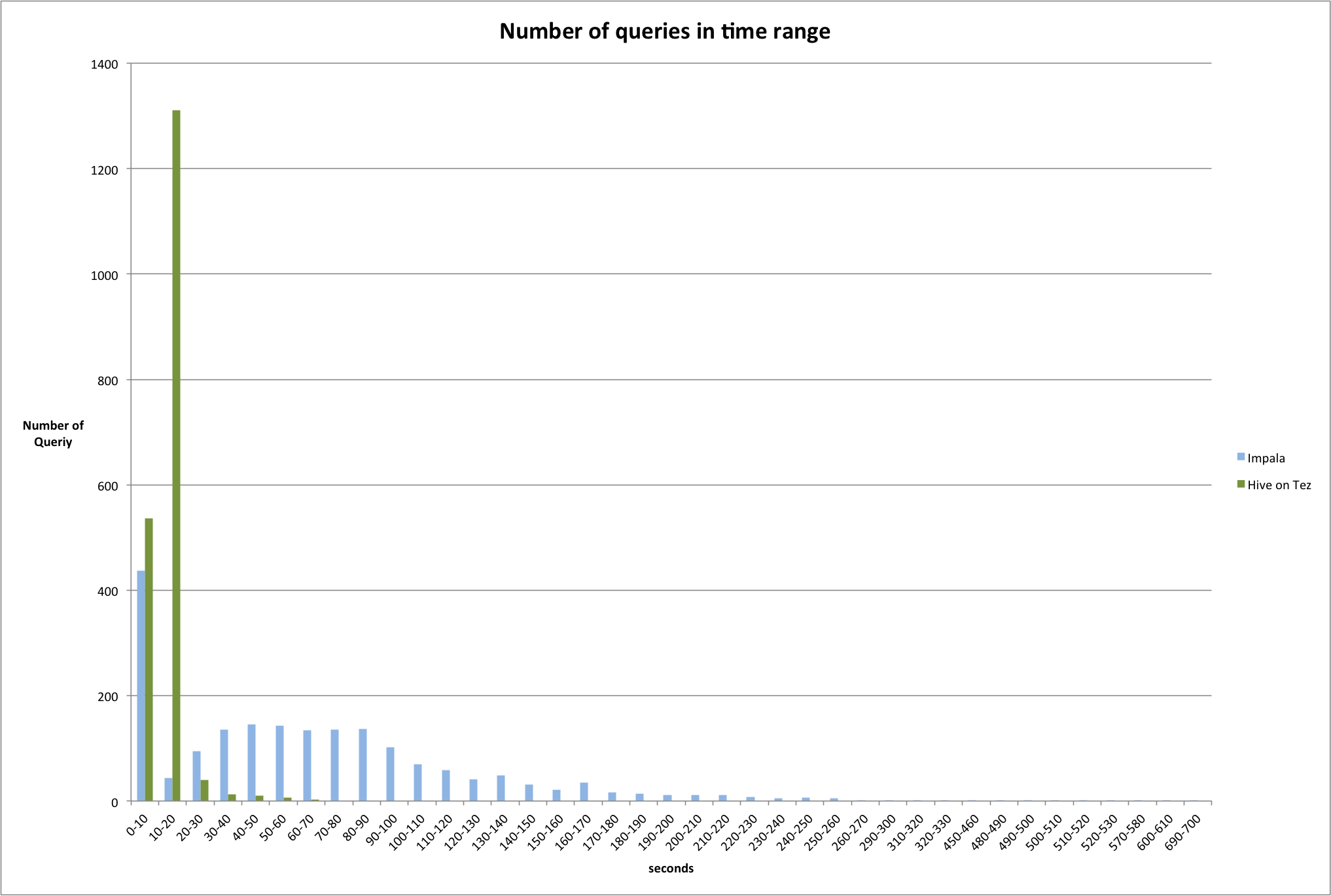
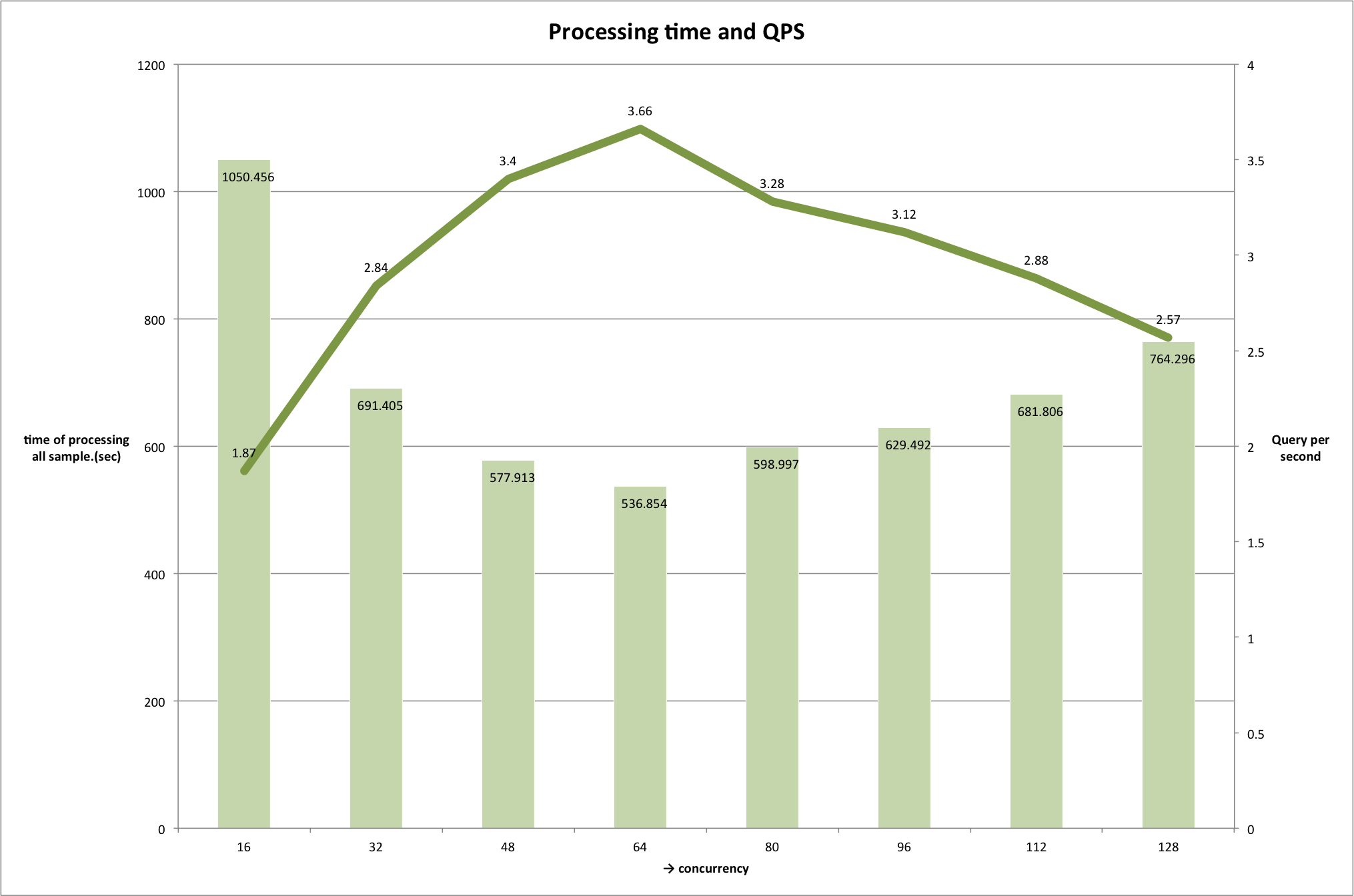
结论 对于Hive on Tez,单个SQL执行时间一般为15秒,会随着并行度的提升而增加。(并行度的限制主要依赖于集群的大小和性能。) 在低负载状态下Impala有非常快的响应时间,但并不适合于SQL并行度非常高的场景。 最后的结论是测试者最后选择了Hive on Tez,因为测试者的场景是每小时至少处理15000个SQL请求。
<!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to you under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --> <workflow-appxmlns="uri:oozie:workflow:0.2"name="map-reduce-wf"> <startto="mr-node"/> <actionname="mr-node"> <map-reduce> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <prepare> <deletepath="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}"/> </prepare> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> <property> <name>mapred.mapper.class</name> <value>org.apache.oozie.example.SampleMapper</value> </property> <property> <name>mapred.reducer.class</name> <value>org.apache.oozie.example.SampleReducer</value> </property> <property> <name>mapred.map.tasks</name> <value>1</value> </property> <property> <name>mapred.input.dir</name> <value>/user/${wf:user()}/${examplesRoot}/input-data/text</value> </property> <property> <name>mapred.output.dir</name> <value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value> </property> </configuration> </map-reduce> <okto="end"/> <errorto="fail"/> </action> <killname="fail"> <message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> </kill> <endname="end"/> </workflow-app>
实战命令
上传example目录到hdfs用户oozie根目录(/user/oozie)下:
1 2 3
su - oozie cd /usr/hdp/current/oozie-server/doc hdfs dfs -put example example